L’intelligence artificielle n’est pas une technologie unique. C’est une galaxie de méthodes, de courants de recherche, de pratiques techniques parfois très différentes. Derrière ce mot-valise se cachent en réalité plusieurs familles, plusieurs façons d’imiter – ou de simuler – des fonctions cognitives humaines.
Comprendre ces familles est essentiel pour toute personne qui souhaite intégrer l’IA dans son entreprise. Cela permet non seulement de mieux choisir les outils adaptés, mais aussi de comprendre leurs limites, leur logique et leur degré d’autonomie.
Ce deuxième article de la série pose donc les bases : quels sont les grands types d’IA ? Comment fonctionnent-ils ? Dans quels cas sont-ils pertinents ? Et pourquoi cette diversité est-elle si importante ?
- Dans cet article
- I. Les trois grandes approches historiques de l’IA
- II. À chaque approche, ses usages
- III. Choisir la bonne IA pour son entreprise
- IV. Ce que vous pouvez faire concrètement pour progresser
- V. À retenir
- VI. Testez vos connaissances
- VII. Partager avec les autres innovateurs
- VIII. Ressources
Les trois grandes approches historiques de l’IA
L’IA symbolique : l’âge des règles
C’est la plus ancienne forme d’intelligence artificielle, parfois surnommée « IA classique » ou « GOFAI » (Good Old-Fashioned Artificial Intelligence). Elle repose sur un principe simple : décrire le monde sous forme de symboles, et manipuler ces symboles à l’aide de règles logiques explicites.
C’est l’IA des systèmes experts des années 1970–80, des programmes de planification, de résolution de problèmes. Elle brille lorsqu’il s’agit de modéliser un raisonnement structuré (ex. : diagnostic médical basé sur des symptômes), mais s’effondre face à des situations floues, bruitées ou ambigües.
Elle a été longtemps dominante, avant d’être dépassée en visibilité par l’apprentissage automatique.
Mais pourquoi parle-t-on ici d’« intelligence » artificielle, alors que le système repose simplement sur des règles codées à la main ? La différence, c’est que ces systèmes symboliques ne se contentent pas d’exécuter une suite d’instructions figées : ils manipulent des concepts, raisonnent, infèrent, combinent des règles pour produire des conclusions nouvelles à partir d’informations fournies par l’utilisateur. Un algorithme classique trie, calcule ou suit un chemin. L’IA symbolique, elle, tente de simuler un raisonnement. Cela peut donner l’illusion d’un dialogue ou d’une déduction, même si tout repose en réalité sur des chaînes logiques prédéfinies.
C’est cette capacité à produire des conclusions nouvelles à partir de prémisses générales qui, historiquement, a justifié l’usage du terme « intelligence » : on n’est plus dans l’automatisation brute, mais dans la formalisation d’un raisonnement — même rigide et limité.
Prenons un exemple concret : un algorithme classique de gestion de stocks va suivre des règles simples du type : « si le stock passe en dessous de X, alors déclencher une commande ». Il s’agit d’une condition fixe, codée en dur, sans adaptation.
Un système expert symbolique, en revanche, pourra intégrer plusieurs règles en cascade :
- Si le produit est périssable ET que la température est élevée, réduire la durée de stockage prévue ;
- Si la demande prévue dépasse le seuil de sécurité, recommander une commande anticipée ;
- Si le fournisseur habituel est en retard ET que le délai critique est atteint, alerter le responsable logistique.
Ces règles peuvent être combinées, hiérarchisées, pondérées, et le système peut en tirer des conséquences nouvelles selon le contexte. Le système ne se contente pas d’exécuter : il déduit. Il applique des chaînes de raisonnement logiques simulant une forme de pensée experte.
Autre exemple : dans un outil de diagnostic médical symbolique, on n’a pas un simple questionnaire à choix fixe. Le système peut poser de nouvelles questions en fonction des réponses précédentes, activer ou désactiver certaines règles selon les symptômes déclarés, et proposer plusieurs hypothèses différentielles à examiner.
C’est cette logique d’inférence, simulée mais structurée, qui distingue l’IA symbolique d’un simple automate ou d’une suite d’instructions figées.
Le machine learning : apprendre au lieu de coder
Plutôt que de tout programmer à la main, pourquoi ne pas laisser la machine apprendre à partir des données ? C’est le pari du machine learning. Ici, on fournit à l’ordinateur un grand nombre d’exemples, et il apprend par lui-même à repérer des régularités pour produire un modèle capable de faire des prédictions.
Il existe plusieurs sous-familles :
- l’apprentissage supervisé (on fournit les bonnes réponses),
- l’apprentissage non supervisé (la machine cherche des structures sans aide),
- l’apprentissage par renforcement (elle apprend en testant, comme un joueur de jeu vidéo).
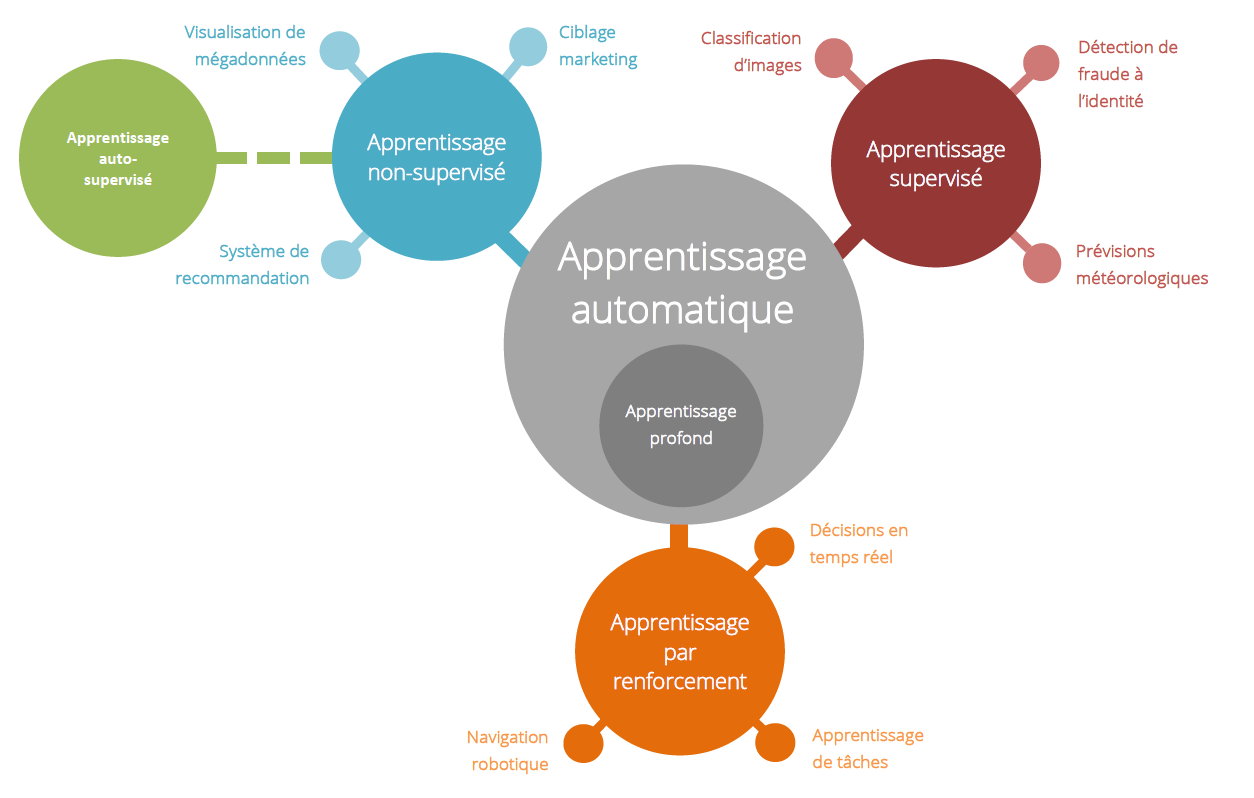
Ce paradigme est aujourd’hui dominant dans la plupart des applications d’IA industrielles.
Le deep learning : l’essor des réseaux de neurones
Le deep learning est une sous-catégorie du machine learning qui repose sur des réseaux de neurones artificiels inspirés du fonctionnement du cerveau. Ces réseaux sont organisés en couches successives qui permettent de détecter des motifs de plus en plus complexes dans les données.
C’est grâce à ces techniques qu’on a vu apparaître les IA capables de reconnaître des visages, de comprendre des phrases, de battre les champions de Go ou de traduire un texte en quelques secondes. Les modèles de langage comme GPT ou Mistral s’inscrivent dans cette logique.
Mais ces modèles ont besoin de quantités gigantesques de données et d’énergie, et sont souvent très peu explicables. Leur puissance est aussi leur faiblesse.
Mais qu’est-ce qu’un réseau de neurones, au juste ? Il s’agit d’un ensemble de petites unités de calcul, appelées « neurones artificiels », organisées en couches. Chaque neurone reçoit des entrées (par exemple, les pixels d’une image ou les mots d’une phrase), applique une opération mathématique simple (une somme pondérée suivie d’une fonction d’activation), puis transmet le résultat aux neurones de la couche suivante.
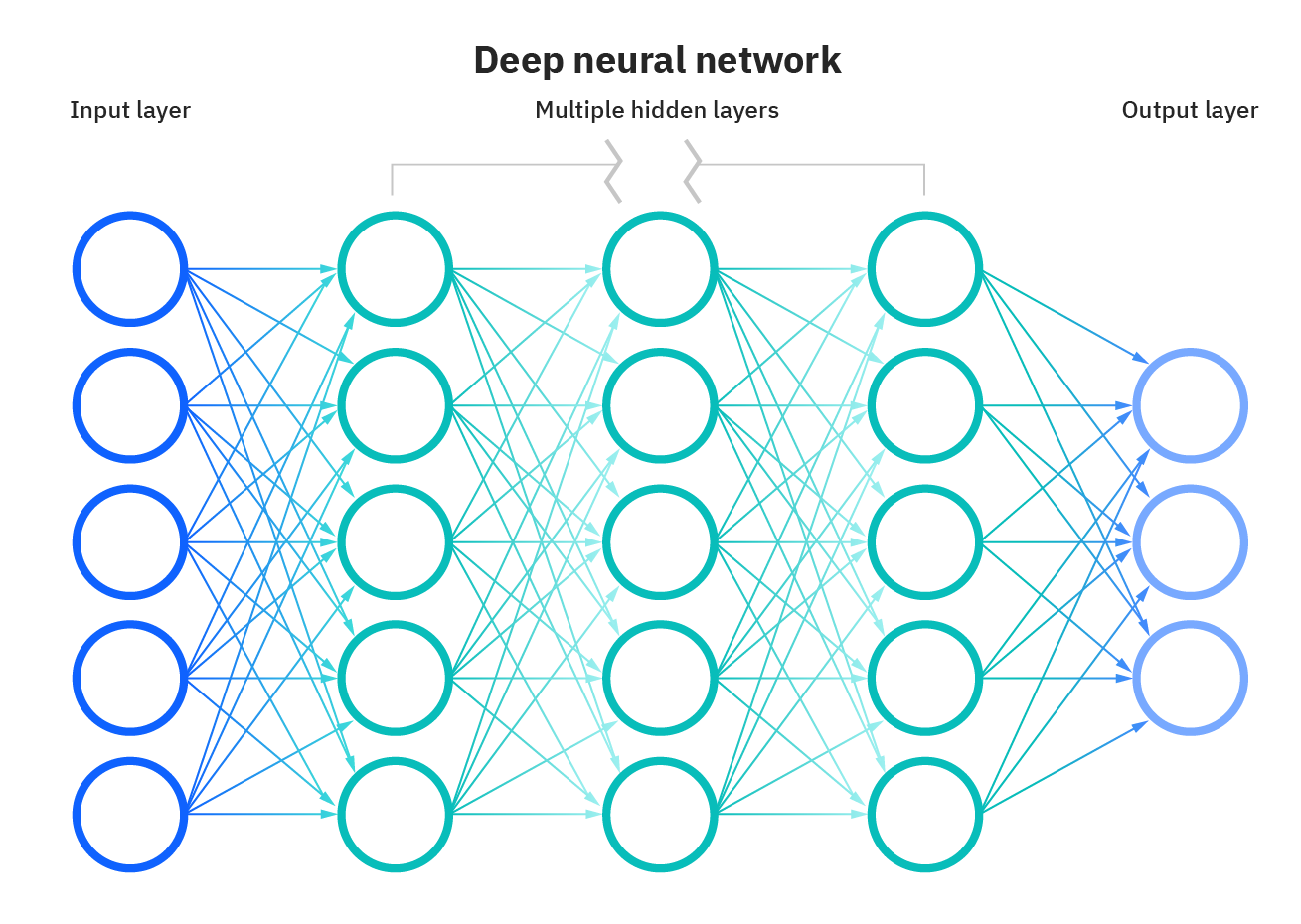
Une couche « voit » les données sous un certain angle. Les premières couches d’un réseau de neurones chargé d’analyser une image détecteront des lignes, des couleurs, des textures. Les couches suivantes repéreront des formes, des contours, des motifs (yeux, nez, etc.), jusqu’à identifier un visage complet. Plus le réseau est profond (nombre de couches élevé), plus il peut modéliser des concepts abstraits.
L’apprentissage se fait en ajustant les poids (ou connexions) entre les neurones, de façon à réduire l’erreur entre la sortie attendue et la sortie réelle. Cela nécessite des millions voire des milliards de paramètres, d’où les ressources colossales mobilisées.
C’est un modèle simple dans son principe, mais extraordinairement puissant lorsqu’il est bien entraîné. On parle de « deep learning » précisément parce que les réseaux sont dits profonds, composés de nombreuses couches successives, capables de capter des représentations complexes et hiérarchisées du monde.
À chaque approche, ses usages
L’IA symbolique dans les systèmes experts
L’IA symbolique est encore utilisée dans des domaines très structurés comme :
- le diagnostic médical (ex. : base de règles pour associer des symptômes à des maladies),
- les moteurs d’inférences en droit ou en fiscalité,
- les assistants décisionnels dans des environnements fermés.
Elle permet de garder un contrôle total sur les règles du système, ce qui en fait une alliée précieuse dans les environnements critiques.
Le machine learning pour la prédiction
On le retrouve partout :
- scoring de crédit dans les banques,
- détection de fraude,
- prévision des ventes,
- maintenance prédictive.
Dès qu’un grand volume de données historiques est disponible, le machine learning excelle pour anticiper des comportements ou classer automatiquement des situations.
Le deep learning pour la perception et la génération
Le deep learning est aujourd’hui la technologie reine pour :
- la vision par ordinateur (détection d’objets, reconnaissance faciale),
- la reconnaissance vocale et la synthèse de la parole,
- la traduction automatique,
- les IA génératives (textes, images, musiques).
C’est aussi la technologie la plus spectaculaire, mais la plus difficile à auditer et à réguler.
Choisir la bonne IA pour son entreprise
Une question de besoin, pas de mode
L’erreur la plus fréquente consiste à choisir une technologie pour son prestige, plutôt que pour sa pertinence. Toutes les entreprises ne doivent pas se précipiter vers le deep learning. Dans bien des cas, une IA symbolique ou un algorithme d’apprentissage simple suffit largement.
Posez-vous d’abord la question :
- Mon problème est-il bien défini ?
- Ai-je beaucoup de données ?
- Les règles sont-elles connues ou à découvrir ?
Dans ce contexte, que recouvre exactement le terme « données » ? Il désigne toutes les informations exploitables par un système d’apprentissage : historiques de ventes, réponses clients, photos d’objets, courriels, enregistrements audio, mesures de capteurs, etc. Mais attention : ces données doivent non seulement être nombreuses, mais aussi cohérentes, bien étiquetées, fiables, et représentatives du problème à résoudre.
Une IA mal nourrie donnera de mauvais résultats, même avec un excellent algorithme. C’est la règle du « garbage in, garbage out » : une IA apprend ce qu’on lui donne. Dans bien des cas, les données d’entreprise sont incomplètes, non structurées, dispersées ou bruitées. La phase de préparation, de nettoyage, d’annotation et de normalisation est donc souvent plus décisive que le choix de l’outil lui-même.
Une question d’explicabilité
Dans certains domaines sensibles – comme la santé, le droit, la finance ou l’assurance – il ne suffit pas qu’un modèle d’IA fonctionne bien. Il faut comprendre comment il fonctionne. Autrement dit, on doit pouvoir expliquer la décision que la machine a produite.
Prenons un exemple : si une IA refuse un crédit à un particulier, il faut que l’organisme financier puisse justifier cette décision en cas de contestation. Était-ce à cause d’un revenu insuffisant ? D’un historique de paiement ? D’un profil statistique ? Un modèle dit « boîte noire » ne permettrait pas de répondre. Cela pose un problème de traçabilité, de confiance, mais aussi de légalité dans certains cas.
De même, dans le domaine médical, une IA qui propose un diagnostic doit pouvoir être confrontée à l’analyse d’un médecin. Si elle identifie un cancer à partir d’un cliché, les cliniciens doivent pouvoir retracer le raisonnement ou les signaux qui ont mené à cette détection. Sans cela, l’IA devient inutilisable en pratique, même si elle est statistiquement efficace.
C’est pourquoi de nombreuses entreprises et institutions préfèrent utiliser des modèles interprétables, même s’ils sont moins sophistiqués : arbres de décision, règles symboliques, régressions linéaires, ou encore des méthodes d’explication locale comme LIME ou SHAP qui rendent les sorties plus lisibles pour un humain.
L’enjeu n’est donc pas purement technique : il est juridique, éthique et stratégique. Une IA inexplicable peut entraîner des biais, des discriminations ou des litiges — avec des conséquences graves sur la réputation, la conformité réglementaire ou la robustesse opérationnelle.
Une question de moyens
Le deep learning demande :
- des volumes massifs de données (souvent plusieurs millions d’exemples pour les images ou les textes, parfois des centaines de gigaoctets à plusieurs téraoctets de données brutes pour entraîner un modèle de langue ou de vision performant),
- des infrastructures coûteuses (GPU, serveurs spécialisés, solutions cloud scalables),
- des compétences rares (data scientists, ingénieurs MLOps, spécialistes du traitement de données massives).
Ce n’est pas forcément hors de portée, mais cela suppose de s’entourer et de raisonner à l’échelle.
Ce que vous pouvez faire concrètement pour progresser
Voici quelques pistes simples pour aller plus loin dès maintenant :
- Tester un outil de machine learning sans coder : essayez Teachable Machine de Google, qui vous permet d’entraîner un modèle en quelques clics à reconnaître vos propres images, sons et postures.
- Lire un billet de blog par semaine : abonnez-vous à des ressources accessibles comme le guide proposé par le gouvernement, Towards Data Science, ou Hugging Face Blog pour suivre l’actualité de l’IA, en particulier de l’IA Open Source (si l’anglais ne vous effraie pas).
- Explorer des cas d’usage français : le site du Hub France IA propose des retours d’expérience concrets d’entreprises françaises.
- Télécharger un outil open source : installez Orange Data Mining (https://orangedatamining.com) pour manipuler des algorithmes IA en glissant-déposant.
- Lire un ouvrage d’introduction : par exemple L’intelligence artificielle, fantasmes et réalités de Jean-Noël Lafargue et Marion Montagne ou encore L’intelligence artificielle n’existe pas de Luc Julia (même si l’auteur est décrié par de nombreux spécialistes).
- Ecouter deux nouveaux épisodes des Carnets de l’IA
- Eneric Lopez, démocratiser l’IA
- Fabrice Lefebvre, entreprises et universités
L’important est de ne pas rester spectateur. Même quelques minutes par semaine suffisent à se familiariser avec les concepts et les usages.
À retenir
- L’intelligence artificielle recouvre plusieurs approches très différentes.
- L’IA symbolique repose sur des règles ; le machine learning sur les données ; le deep learning sur des réseaux de neurones.
- Chaque approche a ses forces, ses faiblesses, ses domaines d’application.
- Le choix de la technologie doit se faire selon le besoin, pas la mode.
- Il faut toujours prendre en compte les questions d’explicabilité, de fiabilité et de ressources.
Testez vos connaissances
[ays_quiz id=’2′]
Partager avec les autres innovateurs
[bbp-derniers flux=reponses forum_id=85520 nombre=8 lien=non titre=oui extrait=oui taille_extrait=100]
Pour poster un message dans les forums, vous devez être identifié comme membre ou lecteur des Cahiers de l’Innovation.
Ressources



